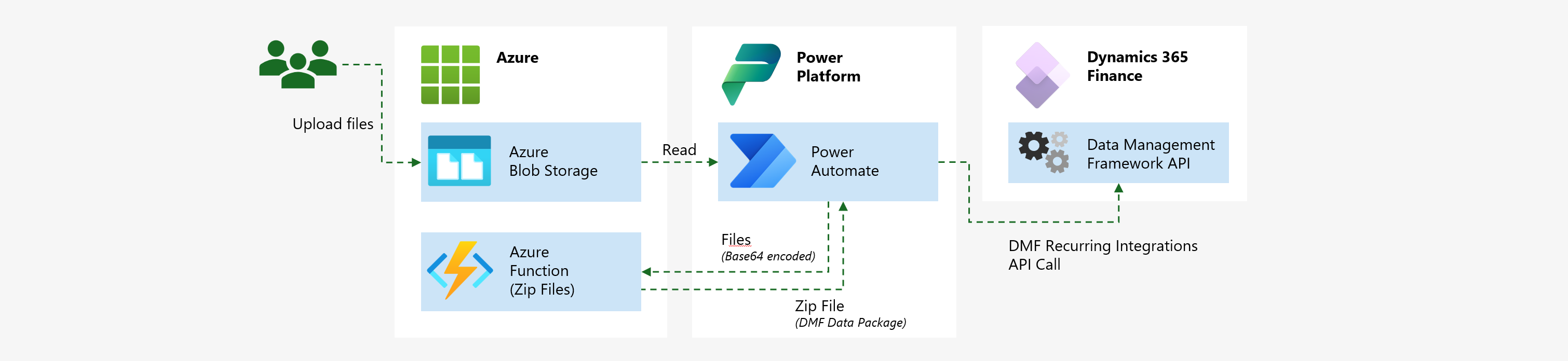
LOW-CODE CUSTOM DATA IMPORT IN FINANCE AND OPERATIONS APPS [ENG]
Motivations
Data integrations are a fundamental requirement for cloud ERP implementations and, historically, in Dynamics have been written in X++ code to read the data, process the data, and eventually save the data on a format Dynamics can understand and use. These manually coded ETL processes also have been, and still are, a common source of problems regarding maintainability, reusability, and particularly performance, as not always have been coded to perform well with large data volumes.
Read more
BIZZSUMMIT 2023 MADRID ¡EVENTO PRESENCIAL! [ES]
El pasado sábado 25 de mayo tuvo lugar el Dynamics 365 Saturday 2023 en las instalaciones de la escuela de negocios ESIC, en Pozuelo de Alarcón (Madrid).
La verdad es que la experiencia fue genial, como siempre, pero especialmente este año por ser el primer evento presencial al que asistía tras la pandemia. No asistía a estos eventos desde el Dynamics 365 Saturday en 2019.
El viernes por la tarde pude dar una sesión sobre gestión del cambio, que es un tema un poco diferente a lo que suelo presentar en eventos, más cerca del negocio y la gestión de proyectos que de la parte técnica. Salió bastante bien, creo yo, pero por desgracia no hay grabación así que no la puedo compartir :(
Read more
RETHINK YOUR #BIZZAPPS INTEGRATIONS FOR PERFORMANCE BASED ON CLOUD DESIGN PATTERNS [ENG]
Introduction
During the last months I have been in contact with a number of Finance and Operations customers facing similar challenges affecting their system’s performance and stability. What do these customers have in common?
- massive data volumes to process and
- data management customizations not designed for performance, either for data processing nor data ingestion, or what we commonly refer as just “Integrations”.
In all cases, performance or throughput bottlenecks were not discovered until it was too late in the implementation project because:
Read more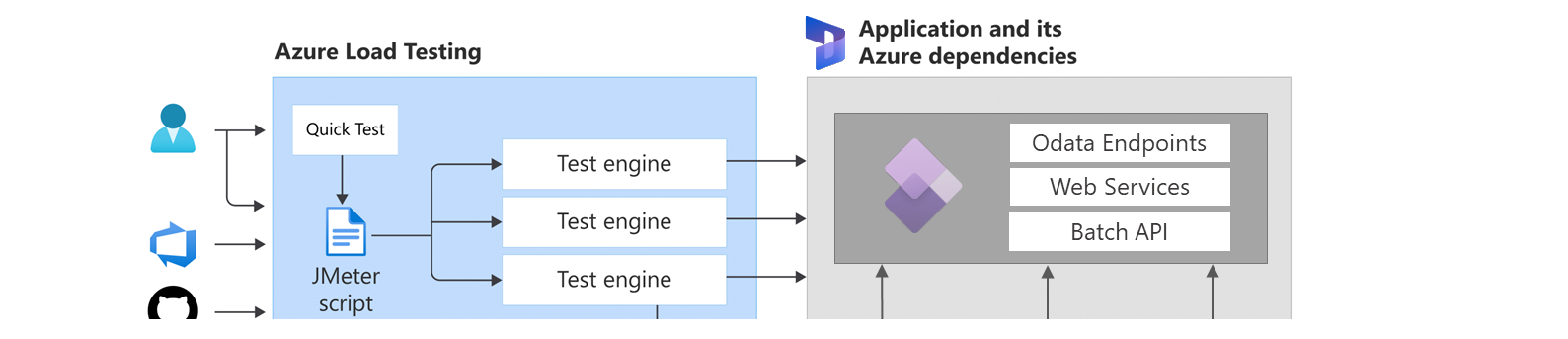
AZURE LOAD TESTING WITH DYNAMICS 365 FINANCE AND OPERATIONS [ENG]
A couple months ago, Microsoft Azure Load Testing (MALT) was made generally available as a fully managed load-testing service that enables generation of high-scale load against our applications. Azure Load Testing has many features that can be leveraged to automate Load Testing in business applications project implementations and hyper care, and also to complement other testing strategies like functional test automation with RSAT:
- Generate high-scale load quickly and easily.
- Identify bottlenecks with actionable insights.
- Build load testing into your DevOps workflows.
- Use a fully managed testing service for Azure.
- Comprehensive security and compliance, built in.
- Keep costs low by paying for only what you use.
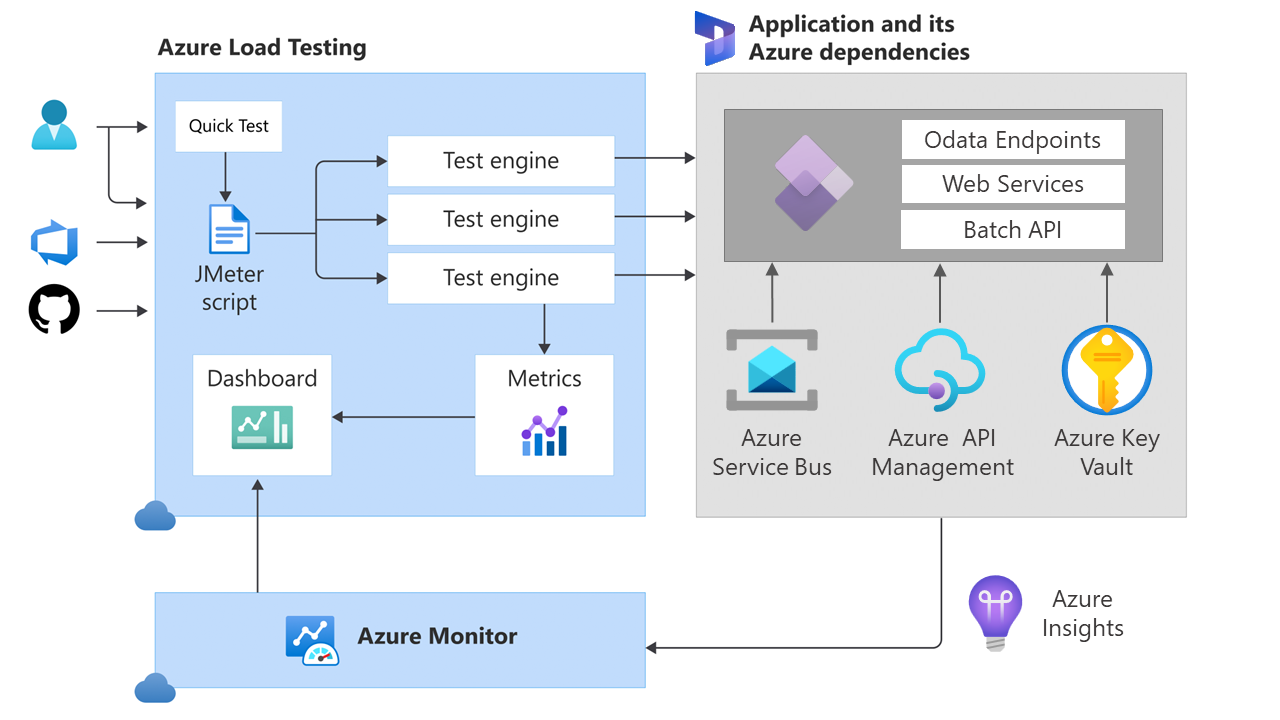
Creating simple load test with MALT is straightforward, as explained in the Quickstart: Create and run a load test with Azure Load Testing, but this will only generate workload against the home page, which is not enough to properly stress a Dynamics applications.
Read more
NEW BLOG, FROM WORDPRESS TO HUGO + AZURE STATIC WEB APP [ENG]
After long period of inactivity (motivated as well by the time I needed to keep WordPress alive, that I could have invested on publishing something) I finally decided to move away from WordPress as the content manager, that I’ve been using for the last 10 years on this site. There are many reasons for that move, WP is certainly easy to use and that’s its best benefit, but it’s also complicated to host and maintain, there is a lot of malware targeting it (due to its massive presence on the web) and it’s heavily dependent on third party plugins.
Read moreNUEVO BLOG, DE WORDPRESS A HUGO + AZURE STATIC WEB APP [ES]
Después de un largo periodo de inactividad (motivado por la cantidad de tiempo que lleva mantener WordPress en línea, que podría haber invertido en publicar algo) he decidido migrar este sitio desde WordPress, que llevo usando más de 10 años como gestor de contenido. Hay muchas razones para moverme, WP es realmente fácil de usar y ese es su principal beneficio, pero es difícil de hospedar y mantener, hay mucho malware orientado a sus páginas (ya que hay muchísimas páginas creadas con él) y depende mucho de plugins desarrollados por terceros.
Read more
CUSTOMER ENGINEERS – HOW WE MAKE OTHERS COOL [ENG]
Note 2024: Customer Engineer role has evolved in name from PFE to CE and now CSA (Cloud Solution Architect), but the same nature persists.
«What exactly is it that you do at work?» is a question everybody in IT has answered many times. I got it asked periodically by my parents and other family members. More than a year ago I wrote another article explaining how I landed here and how you can do it as well.
Read more
ARE YOU A CAREER PLANNER OR A CAREER EXPLORER? [ENG]
First time I heard the question “where do you see yourself in 5 years” just after joining Microsoft, the first answer that came to my mind was «fired».
Then I understood my manager was suggesting me to have a long/mid-term career plan looking forward. «Fair enough, that sounds reasonable». And assumed I was not about to be fired, which was a nice perspective.
«Awesome, let’s write a plan…» … but it was not that easy. As of today, years later, my plan is yet to be completed. I started and modified and quitted that plan countless times.
Read more
LEARNING ON BAD TIMES. ON IMPACT, CAREER DEVELOPMENT... AND CRISIS [ENG]
Something I discovered when I joined Microsoft (I had never thought that way on my previous employers) is measuring your results based on the “Impact” you create.
Measuring personal success and career development based on your impact is of course an interesting way to go, but impact itself is sort of a philosophical, metaphysical, term that turns out difficult to translate into actionable items and measurable results for those with a practical problem-solving mindset like myself. Therefore, career and personal development requires intentional thinking around this topic if you really want to succeed.
Read more
EMPOWER EVERY PERSON… INCLUDING YOURSELF! – MY (SHORT) STORY IN MICROSOFT [ENG]
I’ll spend next week in the Microsoft offices in Lyngby (Denmark) where, as you might know, an important part of the Dynamics 365 Finance and Operations engineering team works.
First time I came to this office was many years ago to attend a job interview that I failed miserably in that engineering team. Here’s the story:
One good day, somehow, I found myself connected to a remote interview with one of my long-time work-related idols: the engineer who, by the time I started learning to develop in Dynamics AX, was maintaining the only X++ focused blog on Internet. I failed this first interview, but he told me something along the lines of (I don’t remember the exact words): “it did not go very well but I will give you a GO today, so you can come here to a full interview cycle in a couple of weeks. Use this time wisely, prepare it better or you won’t do it.”. I prepared the best I could, came there, attend and failed 4 interviews in a row. When the hiring manager told me I was not going to get an offer, it was not of any surprise. I came back home frustrated and mad at me for the lost opportunity.
Read more