Replantea tus integraciones #BizzApps para rendimiento según patrones de diseño en la nube
Introducción
Durante los últimos meses he estado en contacto con varios clientes de Finance and Operations que afrontaban retos similares que afectaban al rendimiento y la estabilidad de sus sistemas. ¿Qué tienen en común estos clientes?
- volúmenes enormes de datos a procesar y
- personalizaciones de gestión de datos no diseñadas pensando en el rendimiento, ya sea para el procesamiento de datos o la ingestión, o lo que comúnmente llamamos “Integrations”.
En todos los casos, los cuellos de botella en rendimiento o throughput no se detectaron hasta que fue demasiado tarde en el proyecto de implantación porque:
- No se consideró el rendimiento al fijar los requisitos de negocio.
- No se tuvo en cuenta el rendimiento durante el diseño global de la arquitectura del sistema (o no hubo un diseño a alto nivel en absoluto).
- No se tuvo en cuenta el rendimiento en el proceso de desarrollo, que en la mayoría de los casos se abordó usando patrones de diseño monolíticos orientados a on‑premise que no encajan bien en entornos cloud masivamente distribuidos.
- Nunca se realizaron pruebas proactivas hasta que la solución estuvo completamente desplegada.
De ese modo, los clientes obtuvieron una solución que hace lo que se esperaba pero que (en muchos casos con amplia diferencia) no era capaz de hacerlo en el tiempo esperado (a veces con penalizaciones regulatorias o interrupciones del sistema). ¿Qué se podría haber hecho diferente?
Al trabajar los requisitos de negocio, el ‘qué’ es tan importante como el ‘cuándo’, el ‘cuánto’ o el ‘cada cuánto’. Los requisitos de negocio deben incluir estimaciones de volumen y expectativas de rendimiento, ya que esos volúmenes fijarán la escala y los objetivos para el diseño, desarrollo y despliegue del sistema.
Con requisitos dimensionados correctamente, se pueden desarrollar y probar rápidamente pilotos tempranos para validar si el throughput esperado se puede cumplir antes de invertir en desplegar el sistema completo.
En caso de duda, elegir la herramienta adecuada para cada tarea y basar las personalizaciones en patrones de diseño cloud bien conocidos proporcionará un arranque más seguro.
Una lección que extraer es que muchas veces los problemas técnicos deben afrontarse como problemas humanos. Ejercita el pensamiento crítico, cuestiona todo requisito que no aporte valor al negocio; cuestiona las decisiones técnicas que vayan a crear más problemas de los que resuelven: al diseñar una arquitectura, la gestión del cambio, la escucha activa y desafiar ideas que crean complejidad artificial son habilidades que deben ejercitarse. Aceptar ideas a ciegas afectará gravemente la extensibilidad, escalabilidad y resiliencia de tus soluciones a largo plazo.
Veamos algunos ejemplos prácticos para ilustrar lo que quiero decir, que espero te aclaren la situación si te encuentras en algo similar:
Llamadas de integración Sync vs Async
En Dynamics F&O (pero ya ocurría lo mismo en Dynamics AX), cuando hablamos de llamadas sincrónicas solemos referirnos a llamadas a endpoints de servicio web (REST o SOAP).
Las llamadas síncronas entre sistemas aislados son problemáticas por muchos motivos, pero en mi opinión la principal es que tras configurar una operación síncrona entre dos sistemas, en teoría dejan de estar aislados. Las llamadas sync provocan que, en la práctica, ambos sistemas deban considerarse uno solo a efectos de mantenimiento, ventanas de indisponibilidad, expectativas de rendimiento y otros aspectos, como comentaré.
Las llamadas síncronas añaden presión al rendimiento porque el sistema llamante espera activamente una respuesta, y una demora puede causar timeouts o errores visibles para el usuario. El sistema origen puede diseñarse para esperar más tiempo, pero ¿qué sentido tiene una llamada síncrona si el sistema puede esperar? Si puede esperar, usa una llamada asíncrona: facilitará la orquestación, hará el sistema más robusto y mantendrá ambos componentes realmente aislados.
Las llamadas síncronas esperan que ambos sistemas escalen al mismo tiempo. Si se esperan grandes volúmenes, tanto el sistema origen debe poder emitir rápido como el sistema destino debe procesar esos mensajes tan rápido como llegan. Se crea una paralelización en cómo ambos sistemas deben evolucionar y reaccionar ante picos de ingestión. Ambos sistemas deben diseñarse para rendir en el peor escenario. De nuevo, se vuelve a hacer a los dos sistemas interdependientes. En escenarios extremos, si uno no puede afrontar la carga y colapsa, el otro no podrá hacer nada y toda la operación puede verse interrumpida. Un diseño async bien pensado seguirá funcionando si un componente falla; podrá ir más lento, pero seguirá procesando y terminará el trabajo.
En resumen, evita las llamadas síncronas cuando sea posible (y empuja a que sea posible). Una llamada sync debe justificarse con una razón de negocio sólida que compense el coste y la complejidad a largo plazo. Normalmente se pueden evitar salvo que se requiera una reacción extremadamente rápida del sistema tras un evento. Como regla: ‘siempre async por defecto’.
Consulta Azure Architecture Center:
Integraciones inbound
Importar datos desde sistemas externos (totalmente de terceros, o desde otros sistemas dentro de la organización) es parte clave del cómputo en la nube y un aspecto crítico del diseño de arquitectura para escalar correctamente.
Todos los clientes citados en la introducción tenían integraciones inbound masivas que soportaban procesos críticos (contabilización de facturas, asientos contables, pedidos de compra, cierre de órdenes de producción, …) en distintos sectores: banca, procesadores de pagos, fabricación, retail, … la lista continúa. La mayoría de estas integraciones no estaban diseñadas para escalar a los niveles que el negocio esperaba, lo que provoca diversos problemas. En muchos casos las personalizaciones o configuraciones limitaban la capacidad de la aplicación estándar para rendir adecuadamente.
Muchas estaban diseñadas como grandes operaciones atómicas síncronas usando servicios web como canal inbound, generando transacciones de base de datos masivas y manteniendo sesiones y transacciones abiertas durante largos periodos, afectando significativamente al rendimiento de otros procesos y sesiones de usuario.
Transacciones de base de datos, diseño básico de tablas e índices o mecanismos fundamentales de concurrencia como el bloqueo de transacciones se ignoraron, limitando mucho la capacidad de Azure SQL para ser eficiente.
Muchas integraciones eran basadas en ficheros, por diseño de los sistemas externos, y usaban tecnologías obsoletas comunes en algunas industrias como FTP, que se mantuvieron por compatibilidad.
En otros casos, esas tecnologías formaban parte del diseño original, bien por haber sido concebidas para on‑premise o porque los diseñadores no eligieron una alternativa mejor. En ocasiones se puede reemplazar por un servicio de almacenamiento cloud más moderno que simplifica operaciones y mejora rendimiento, resiliencia y seguridad.
Los equipos técnicos no tenían una comprensión precisa de las expectativas del negocio respecto al resultado de esas integraciones. Eso condujo a decisiones técnicas erróneas basadas en suposiciones no confirmadas. Cuando se cuestionaron esas decisiones, los responsables de negocio no pusieron problemas en cambiar el diseño técnico para mejorar throughput y resiliencia.
¿Cómo diseñar integraciones inbound a escala? (lo estándar es rápido, no lo bloquees)
Cuando sea posible, usa módulos estándar como el Data Management Framework para gestionar integraciones. Puede ser necesario crear un componente middleware para afrontar sistemas externos (como una API personalizada o una solución basada en colas), pero siempre valora si la importación/exportación de datos puede delegarse finalmente a componentes estándar para mejorar mantenimiento y extensibilidad.
Considera cómo debe reaccionar el sistema cuando Dynamics está en mantenimiento o no disponible. Por ejemplo, si F&O cae, los servicios web internos estarán inaccesibles, pero componentes externos en Azure como una cola de Azure Service Bus tendrán una alta disponibilidad. Aprovecha las fortalezas de cada componente cloud para diseñar una solución robusta.
¿Cómo reaccionará el sistema ante picos repentinos y masivos de volumen, como procesos que importan grandes operaciones diarias durante la noche? ¿Se pueden pre‑procesar esos datos usando soluciones de datos de Azure (pipelines en Azure Synapse Analytics, Azure Data Factory, Azure Databricks, …)? Así los volúmenes que llegan a Dynamics pueden reducirse y transformarse a una estructura más adecuada para el rendimiento.
Acordad con los responsables funcionales cuál es el conjunto mínimo de datos que debe considerarse atómico (la pieza mínima que se importa o se rechaza por completo) para cada operación. Esta información es clave para diseñar operaciones paralelas multi‑hilo y multi‑servidor, tanto dentro de Dynamics (por ejemplo mediante Batch tasks) como en herramientas externas de procesamiento de datos.
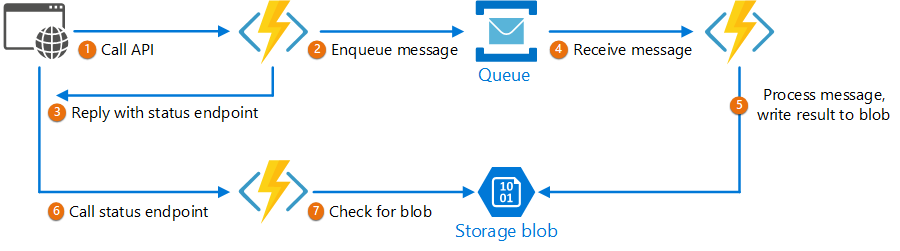
Un patrón robusto y escalable para integraciones inbound es usar queue‑based load leveling: el sistema externo coloca paquetes de datos en una cola (por ejemplo, Azure Service Bus) y el sistema destino consume y procesa esos paquetes de forma asíncrona tan rápido como sea posible. Ante picos, los datos se encolan y la parte backend los procesa manteniendo la estabilidad.
Diseñar un sistema basado en colas para un entorno altamente concurrente no es trivial. Requiere comprender cómo gestionar la concurrencia en todos los componentes y añadir comprobaciones de seguridad para evitar contenciones. Servicios cloud como Azure Service Bus facilitan este diseño frente a intentar crear colas mediante tablas en bases de datos (no diseñadas para ello). Si te interesa, aquí un ejemplo: https://learn.microsoft.com/en-us/answers/questions/222532/sql-server-how-to-design-table-like-a-queue.
Otra solución escalable es usar un patrón de coreografía para distribuir la carga entre componentes (pipelines, Batch Jobs internos, jobs de import/export, …). La concurrencia es un tema complejo que podemos abordar en otro post si hay interés.
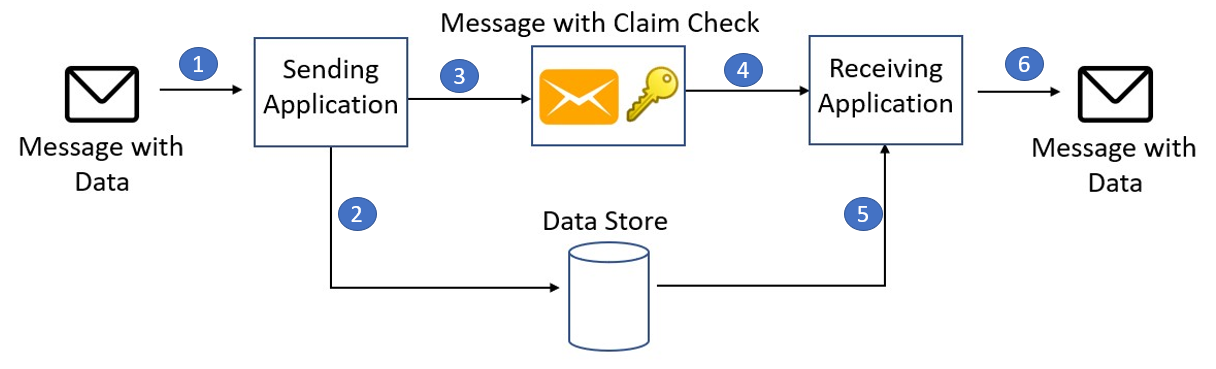
Si los paquetes de datos son demasiado grandes para la cola, se puede usar el claim‑check pattern: almacenar temporalmente el paquete en un almacenamiento y encolar sólo la información mínima para que el destino sepa dónde recuperar la carga completa cuando proceda. Pero antes, valora si los paquetes pueden pre‑procesarse para que lleguen a Dynamics en trozos manejables.
Consulta Azure Architecture Center:
- Design patterns – Queue-Based Load Leveling
- Design patterns – Claim-Check
- Design patterns – Choreography
Integraciones outbound
Los principios para integraciones outbound son parecidos a los inbound en cuanto a procesar y transportar información de forma aislada y asíncrona cuando sea posible, pero hay particularidades en Finance and Operations:
De nuevo, crea los fundamentos de los procesos de exportación basándolos en funcionalidades estándar, como el Data Management Framework. Puede que necesites personalizaciones para permitir que sistemas externos disparen trabajos de exportación y recuperen resultados, pero usar DMF ayuda en rendimiento, extensibilidad y mantenimiento, y respeta las restricciones de seguridad internas.
¿Pueden los trabajos de exportación iniciarse a partir de datos ya exportados? Por ejemplo, si ya exportas datos a Azure Data Lake puedes diseñar pipelines que lean del lago sin interactuar con Dynamics. Herramientas de Data Analytics pueden procesar y transformar esos datos para cumplir requisitos de terceros.
Características como Business Events son un buen disparador para soluciones basadas en Publisher-Subscriber u orquestaciones de mensajería. No se recomienda usar business events para exportar datos, sino como notificaciones: por ejemplo, notificar que un paquete está listo para ser consumido, de modo que el sistema externo que va a leerlo pueda hacerlo cuando los datos estén preparados.
Si un evento de negocio debe transportar mucha información (algo que debe evitarse), puedes aplicar también el claim‑check pattern: almacenar datos en un almacenamiento apropiado y enviar en el evento sólo una referencia. Hay que poner controles para evitar disparar demasiados eventos en entidades con alta transaccionalidad.

- Diseños que agrupan transacciones para exportar paquetes completos tienden a funcionar mejor que sincronizar entidades en tiempo real. Las integraciones en tiempo real impactan notablemente en el rendimiento y deben evitarse.
Imitar integraciones en tiempo real va en contra de mantener sistemas aislados. Si la integridad en tiempo real es un requisito de negocio fuerte, intenta usar la exportación estándar a Azure Data Lake y emplea el lago como fuente para sistemas externos. ADL dispone de mecanismos como el [Change feed folder] para detectar cambios.
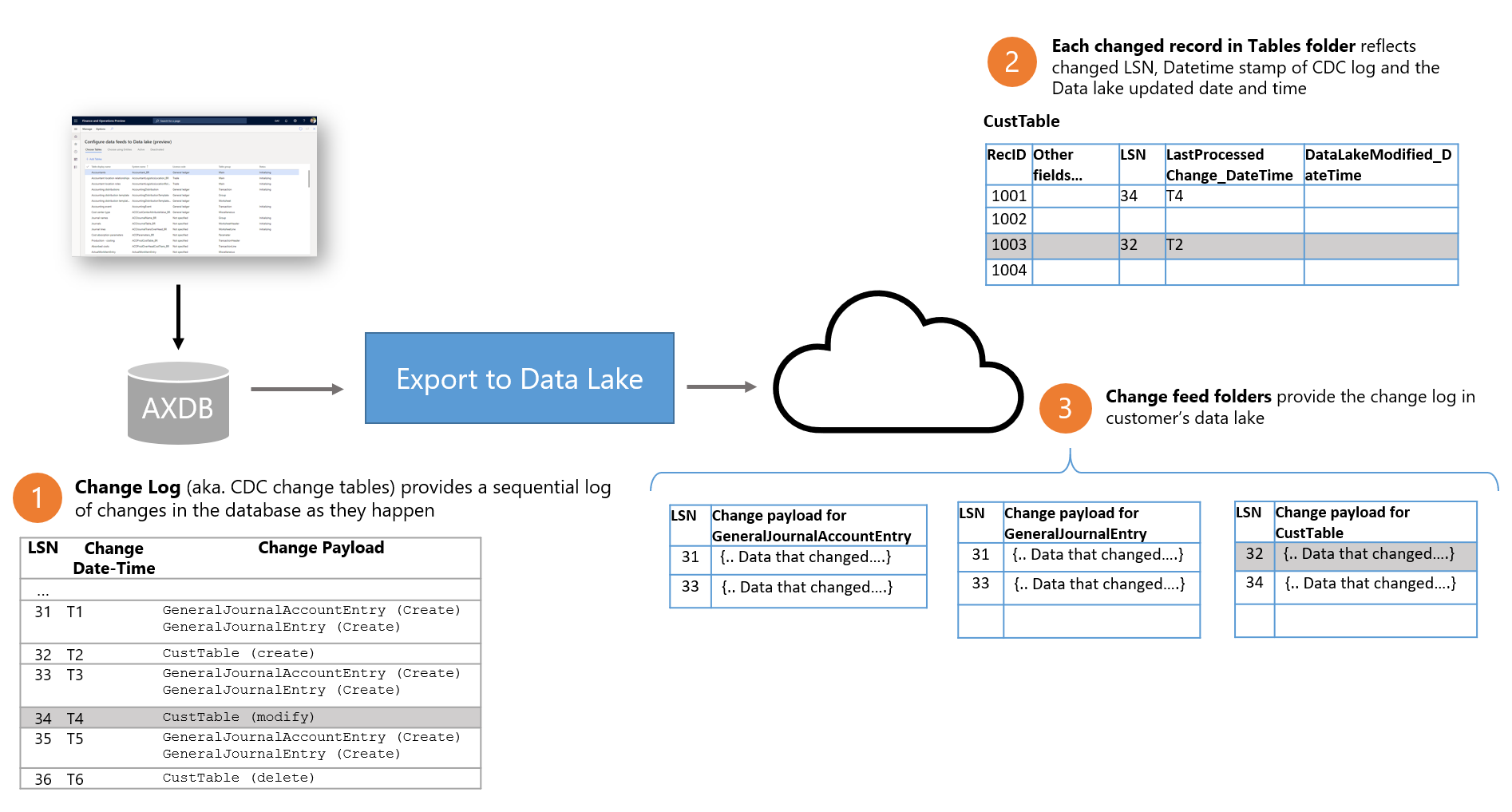
Consulta Azure Architecture Center:
- Design patterns – Publisher-Subscriber
- Export to Azure Data Lake overview
- Change data in Azure Data Lake.
Conclusiones
Desde las fases más tempranas con los responsables de negocio hasta la implementación técnica final, hay que pensar no solo en diseñar un sistema que haga lo que se espera, sino que pueda hacerlo a la escala y velocidad adecuadas. ‘Funciona en mi máquina’ nunca es suficiente; debe funcionar en producción con volúmenes y concurrencia reales.
Diseña con requisitos de producción en mente: ¿cómo vas a monitorizar el sistema en su conjunto, incluidas las integraciones? ¿Quién será responsable de reaccionar ante errores? ¿Qué herramientas tendrán esos equipos para diagnosticar los distintos componentes? Esas preguntas son claves para “poner en producción” tus integraciones.
A menudo, componentes individuales se diseñan y prueban aisladamente en entornos de desarrollo, y sólo se verifica el “happy path”. Un sistema crítico debe evaluarse como un todo, validando escenarios extremos, tests de estrés, incluyendo todos los componentes y datos de tamaño de producción para validar requisitos de rendimiento y resiliencia. Hacer cambios cuando el sistema ya está terminado será más caro y traumático que considerar un buen diseño desde el inicio y durante todas las fases.
Sigue leyendo:
- Design principles for Azure applications
- Use the best data store for your data
- Artificial intelligence (AI) architecture design